RocketMQ这样做,压测后性能提高30%

作者 | 丁威
来源 | 中间件兴趣圈
从官方这边获悉,RocketMQ在4.9.1版本中对消息发送进行了大量的优化,性能提升十分显著,接下来请跟着我一起来欣赏大神们的杰作。
根据RocketMQ4.9.1的更新日志,我们从中提取到关于消息发送性能优化的【Issues:2883】,详细链接如下:具体优化点如截图所示:
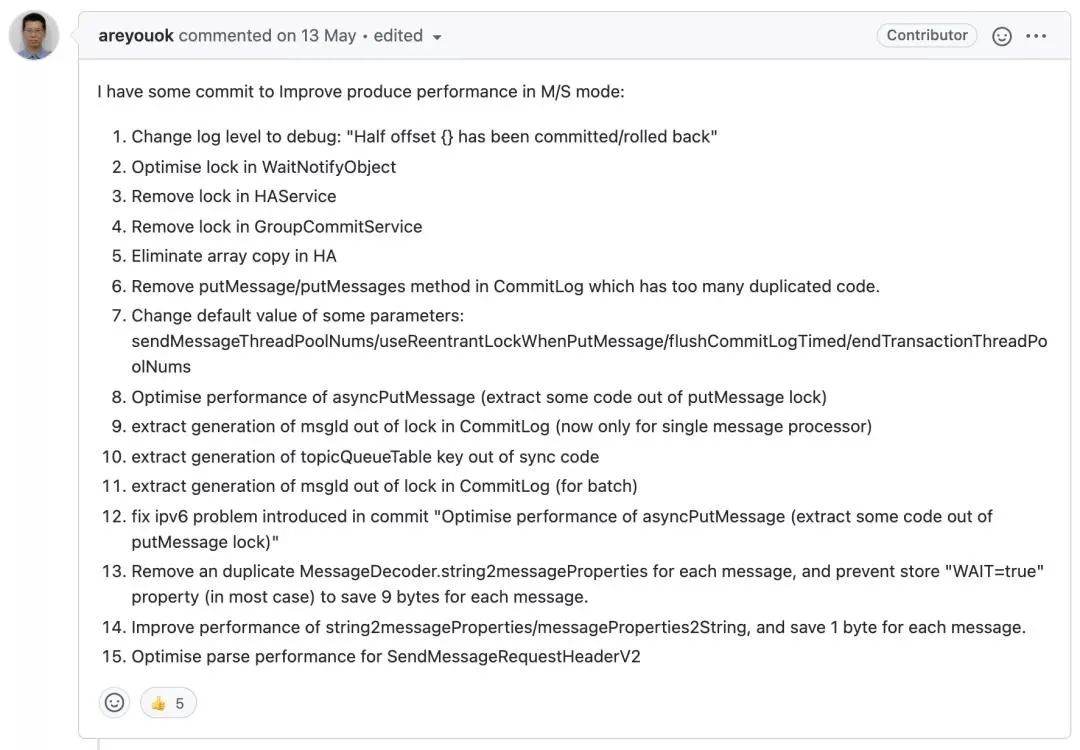
首先先尝试对上述优化点做一个简单的介绍:
对WaitNotifyObject的锁进行优化(item2)
移除HAService中的锁(item3)
移除GroupCommitService中的锁(item4)
消除HA中不必要的数组拷贝(item5)
调整消息发送几个参数的默认值(item7)
sendMessageThreadPoolNums
useReentrantLockWhenPutMessage
flushCommitLogTimed
endTransactionThreadPoolNums
减少琐的作用范围(item8-12)
通过阅读上述的变更,总结出优化手段主要包括如下三点:
移除不必要的锁
降低锁粒度(范围)
修改消息发送相关参数
接下来结合源码,从中挑选具有代表性功能进行详细剖析,一起领悟Java高并发编程的魅力。


移除不必要的锁
本次性能优化,主要针对的是RocketMQ同步复制场景。
我们首先先来简单介绍一下RocketMQ主从同步在编程方面的技巧。
RocketMQ主节点将消息写入内存后, 如果采用同步复制,需要等待从节点成功写入后才能向消息发送客户端返回成功,在代码编写方面也极具技巧性,时许图如下图所示:
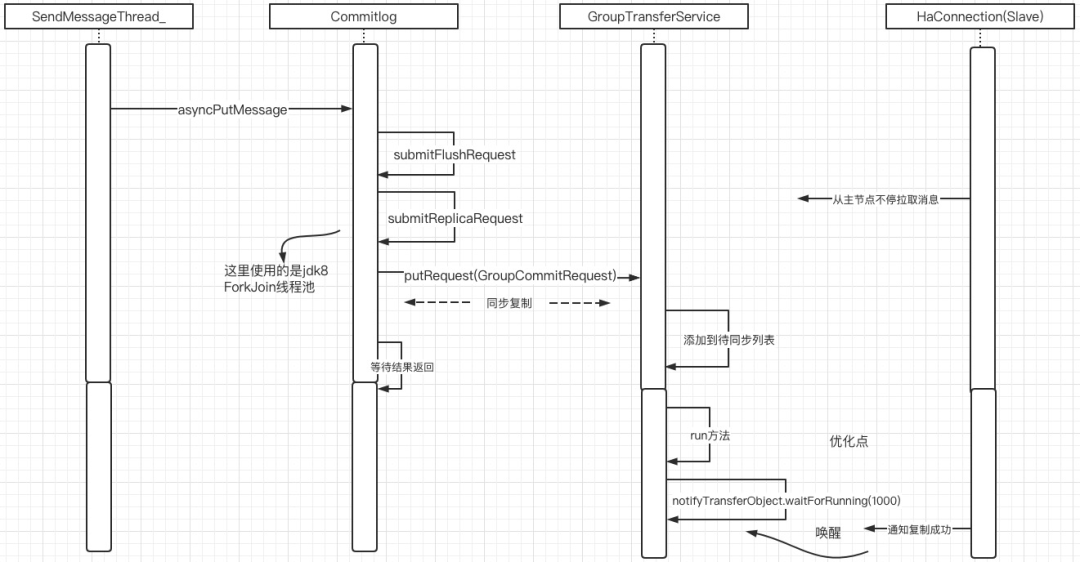
温馨提示:在RocketMQ4.7版本开始对消息发送进行了优化,同步消息发送模型引入了jdk的CompletableFuture实现消息的异步发送。
核心步骤解读:
消息发送线程调用Commitlog的aysncPutMessage方法写入消息。
Commitlog调用submitReplicaRequest方法,将任务提交到GroupTransferService中,并获取一个Future,实现异步编程。值得注意的是这里需要等待,待数据成功写入从节点(内部基于CompletableFuture机制的内部线程池ForkJoin)。
GroupTransferService中对提交的任务依次进行判断,判断对应的请求是否已同步到从节点。
如果已经复制到从节点,则通过Future唤醒,并将结果返回给消息发送端。
GroupTransferService代码如下图所示:
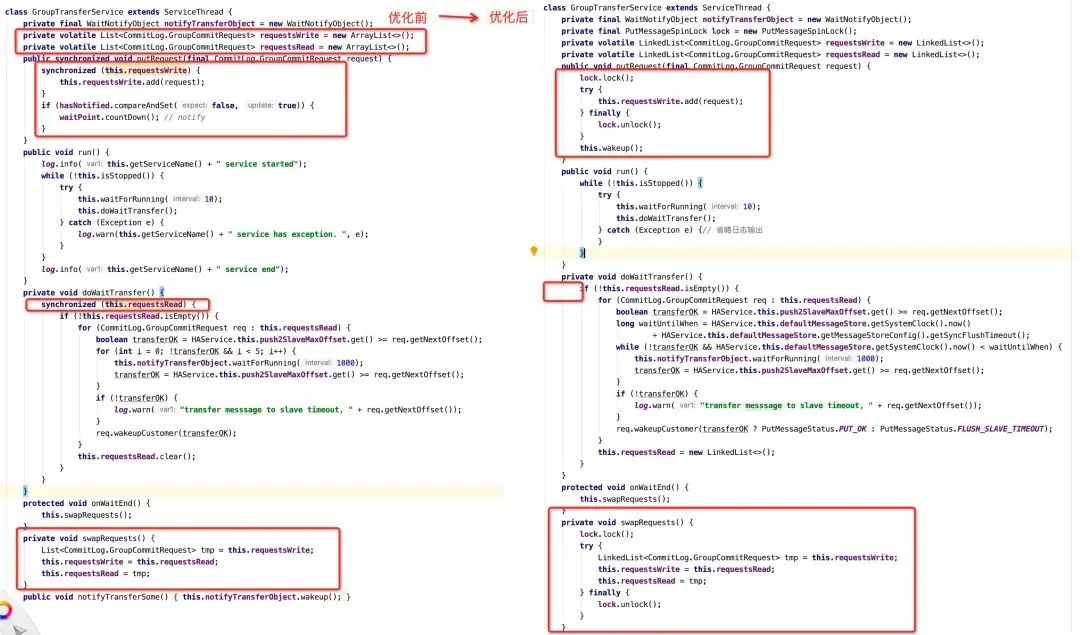
为了更加方便大家理解接下来的优化点,首先再总结提炼一下GroupTransferService的设计理念:
首先引入两个List结合,分别命名为读、写链表。
外部调用GroupTransferService的putRequest请求,将存储在写链表中(requestWrite)。
GroupTransferService的run方法从requestRead链表中获取任务,判断这些任务对应的请求的数据是否成功写入到从节点。
每当requestRead中没有数据可读时,两个队列进行交互,从而实现读写分离,降低锁竞争。
新版本的优化点主要包括:
更改putRequest的锁类型,用自旋锁替换synchronized
去除doWaitTransfer方法中多余的锁
1.1 使用自旋锁替换synchronized
正入下图所示,GroupTransferService向外提供接口putRequest,用来接受外部的同步任务,需要对ArrayList加锁进行保护,往ArrayList中添加数据属于一个内存操作,操作耗时小。

故这里没必要采取synchronized这种synchronized,而是可以自旋锁,自旋锁的实现非常轻量级,其实现如下图所示:

整个锁的实现就只需引入一个AtomicBoolean,加锁、释放锁都是基于CAS操作,非常的轻量,并且自旋锁不会发生线程切换。
1.2 去除多余的锁
“锁”的滥用是一个非常普遍的现象,多线程环境编程是一个非常复杂的交互过程,在编写代码过程中我们可能觉得自己无法预知这段代码是否会被多个线程并发执行,为了谨慎起见,就直接简单粗暴的对其进行加锁,带来的自然是性能的损耗,这里将该锁去除,我们就要结合该类的调用链条,判断是否需要加锁。
整个GroupTransferService中在多线程环境中运行需要被保护的主要是requestRead与requestWrite集合,引入的锁的目的也是确保这两个集合在多线程环境下安全访问,故我们首先应该梳理一下GroupTransferService的核心方法的运作流程:

doWaitTransfer方法操作的主要对象是requestRead链表,而且该方法只会被GroupTransferService线程调用,并且requestRead中方法会在swapRequest中被修改,但这两个方法是串行执行,而且在同一个线程中,故无需引入锁,该锁可以移除。
但由于该锁被移除,在swapRequests中进行加锁,因为requestWrite这个队列会被多个线程访问,优化后的代码如下:

从这个角度来看,其实主要是将锁的类型由synchronized替换为更加轻量的自旋锁。

降低锁的范围
被锁包裹的代码块是串行执行,即无法并发,在无法避免锁的情况下,降低锁的代码块,能有效提高并发度,图解如下:

如果多个线程区访问lock1,lock2,在lock1中domSomeThing1、domSomeThing2这两个方法都必须串行执行,而多个线程同时访问lock2方法,doSomeThing1能被多个线程同时执行,只有doSomething2时才需要串行执行,其整体并发效果肯定是lock2,基于这样理论:得出一个锁使用的最佳实践:被锁包裹的代码块越少越好。
在老版本中,消息写入加锁的代码块比较大,一些可以并发执行的动作也被锁包裹,例如生成offsetMsgId。
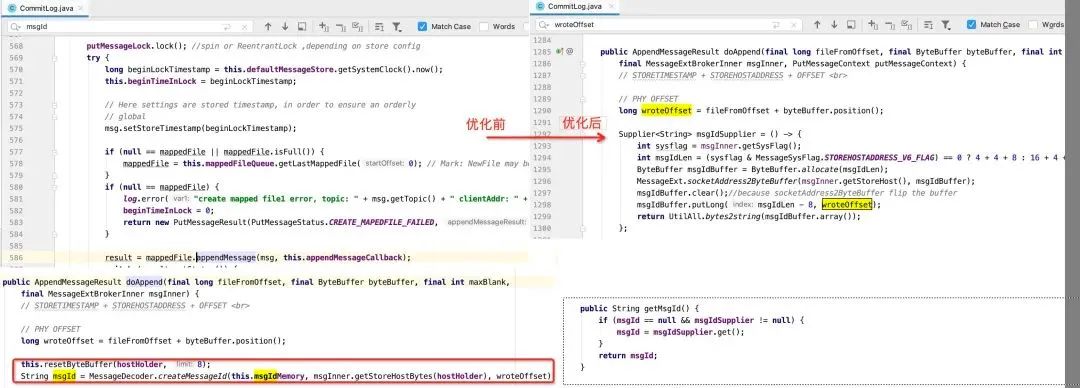
新版本采用函数式编程的思路,只是定义来获取msgId的方法,在进行消息写入时并不会执行,降低锁的粒度,使得offsetMsgId的生成并行化,其编程手段之巧妙,值得我们学习。

调整消息发送相关的参数
1、sendMessageThreadPoolNums
Broker端消息发送端线程池数量,该值在4.9.0版本之前默认为1,新版本调整为操作系统的CPU核数,并且不小于4。该参数的调整有利有弊。提高了消息发送的并发度,但同时会导致消息顺序的乱序,其示例图如下同步发送下不会有顺序问题,可放心修改

在顺序消费场景,该参数不建议修改。在实际过程中应该对RocketMQ集群进行治理,顺序消费的场景使用专门集群。
2、useReentrantLockWhenPutMessage MQ消息写入时对内存加锁使用的锁类型,低版本之前默认为false,表示默认使用自旋锁;新版本使用ReentrantLock。自旋主要的优势是没有线程切换成本,但自旋容易造成CPU的浪费,内存写入大部分情况下是很快,但RocketMQ比较依赖页缓存,如果出现也缓存抖动,带来的CPU浪费是非常不值得,在sendMessageThreadPoolNums设置超过1之后,锁的类型使用ReentrantLock更加稳定。
3、flushCommitLogTimed,首先我们通过观察源码了解一下该参数的含义:

其主要作用是控制刷盘线程阻塞等待的方式,低版本flushCommitLogTimed为false,默认使用CountDownLatch,而高版本则直接使用Thread.sleep。猜想的原因是刷盘线程比较独立,无需与其他线程进行直接的交互协作,故无需使用CountDownLatch这种专门用来线程协作的“外来和尚”。
4、endTransactionThreadPoolNums,主要用于设置事务消息线程池的大小。

新版本主要是可通过调整发送线程池来动态调节事务消息的值,这个大家可以根据压测结果动态调整。

《新程序员003》正式上市,50余位技术专家共同创作,云原生和数字化的开发者们的一本技术精选图书。内容既有发展趋势及方法论结构,华为、阿里、字节跳动、网易、快手、微软、亚马逊、英特尔、西门子、施耐德等30多家知名公司云原生和数字化一手实战经验!


☞监控员工离职倾向系统已被深信服下架;热度超微信、QQ的元宇宙App主动下架;IntelliJ平台删除Log4j组件|极客头条 ☞历史上的今天:编程语言Julia公开发布;IBM诞生 ☞同样是 ARM,为什么 Mac 会成功,Windows 却输得一败涂地?
[广告]赞助链接:
关注数据与安全,洞悉企业级服务市场:https://www.ijiandao.com/
让资讯触达的更精准有趣:https://www.0xu.cn/
 关注KnowSafe微信公众号
关注KnowSafe微信公众号随时掌握互联网精彩
- Orion-Visor高颜值、现代化的智能运维&轻量堡垒机平台
- 高德地图“空中版”发布:飞行器也能导航了
- R星向黑客发感谢声明 去年共向他们支付仅1.7万美元
- 思科披露Tinyproxy漏洞可导致远程代码执行,超过50000台主机受影响
- 百度发打假声明:目前文心一言无官方 App;吴恩达LeCun直播回怼马斯克:汽车都没发明要什么安全带|极客头条
- 大展宏“兔”!华为中国兔年定制红包封面来了
- 分布式系统的“三驾马车” | 历史上的今天
- Windows版Flutter应用开发体验远达不到Android和iOS的水平
- 普京下令各部门机构设立IT安全部门
- 华为车海平:共建先进工业网络 共创智能制造新价值
- 等待十年,史上第一个 64 位版 Visual Studio 将于今夏公开首个预览版!
- 年终福利 | “社区之星”(年度贡献者)成长故事征集




