Fuzz学习记录

本文为看雪论坛优秀文章
看雪论坛作者ID:Nameless_a
当前需要解决的问题
优化思路
AFL
优化思路
crashes如何打开
afl-fuzz的变异策略

个人对afl-fuzz的理解
fuzz tcpdump
fuzz目标tcpdump的生成
报错的初始化配置:
sudo suecho core >/proc/sys/kernel/core_pattern
指令:
afl-fuzz -i fuzz_in -o fuzz_out ./tcpdump -ee -vv -nnr @@探究种子的重新筛选对fuzz的运行效率有无影响
数据一
跑了23个小时后的数据重新跑(未cmin) 操作系统ubnutu20

跑了23个小时的数据(cmin后)

数据二
跑了23个小时后的数据重新跑(未cmin)ubnutu18

跑了23个小时后的数据重新跑(cmin后)ubnutu18

择种算法
sklearn的kmeans算法
kmeans

聚类效果评判
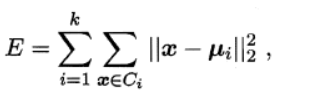

kmeans++

关于种子的模型
afl-showmap -o mapfile ./tcpdump -ee -vv -nnr ./queue/id:000000,orig:small_capture.pcap000087:1000142:1000248:1000928:1001092:1001322:1001382:1002101:4002141:1002184:1002346:1002403:2002589:1003031:2003072:1003160:2003220:1003251:1003567:1003574:2003827:1003984:2004084:1004178:4
hamming距离

如何将种子转换为二进制数并且保存
下面分布详细记录过程:
步骤一:通过python读取文件名,然后对每一个文件调用showmap得到信息文本文件
python获得当前目录下所有文件名:
import ospath = "文件目录"datanames = os.listdir(path)for i in datanames:print(i)
import osinpath = "./tcpdump/queue"outpath= "./tcpdump/save_showmap"datanames = os.listdir(inpath)a=1##print(cmd)for i in datanames:outname=outpath+'/'+str(a)inname=inpath+'/'+icmd="afl-showmap -o {} ./tcpdump/tcpdump -ee -vv -nnr {}".format(outname,inname)os.system(cmd)a=a+1
步骤二:通过python脚本,将信息文本文件转换为二进制数并以文本形式保存
import osinpath='./tcpdump/save_showmap'outpath='./tcpdump/save_binary'file_path = inpathdatanames = os.listdir(file_path)a=1for i in datanames:inname=inpath+'/'+str(a)outname=outpath+'/'+str(a)f_in=open(inname,'r')f_out=open(outname,'w')line=f_in.readline()last_number=1while line:now_number=int(line[:6])##print(now_number)for j in range(last_number,now_number):f_out.write(str(0)+'\n')f_out.write(str(1)+"\n")last_number=now_number+1line=f_in.readline()f_in.close()f_out.close()a+=1
新思路:将种子对应成一个大数
a=1<<1000000print(a)
a=1b=11c=((a<<100000)-1) | (b<<100000)print(c)
a=1b=11c=((a<<100000)-1) | (b<<100000)def count_one(x):s=0while(x):if (x & 1):s+=1x=x>>1return sprint(count_one(c))
将种子转换成大数的脚本
import osinpath='./tcpdump/save_showmap'outpath='./tcpdump/save_bignum'file_path = inpathdatanames = os.listdir(file_path)a=1for i in datanames:inname=inpath+'/'+str(a)outname=outpath+'/'+str(a)f_in=open(inname,'r')f_out=open(outname,'w')big_number=0line=f_in.readline()while line:now_number=int(line[:6])big_number+=1<<now_numberline=f_in.readline()f_out.write(str(big_number))f_in.close()f_out.close()a+=1
pyclusring库下的kmeans聚类
先造个沙堡!
#以下代码为:生成随机散点图from turtle import colorimport numpy as npimport matplotlib.pyplot as pltfrom pyclustering.cluster.center_initializer import kmeans_plusplus_initializerfrom pyclustering.cluster.kmeans import kmeans## 前面是安装的库cluster_num=20def draw_line(a,b):a_x=a[0]a_y=a[1]b_x=b[0]b_y=b[1]plt.plot([a_x,b_x], [a_y,b_y],linewidth=1,color='green')def add_line_between_center_and_members(cs,group,x): # cs:聚类中心 group:二维数组表示的分组情况 x:原始的二维数组for i in range(0,cluster_num):for j in group[i]:draw_line(cs[i],x[j])def draw_initial_point(x):x1=[]y1=[]for i in x:x1+=[i[0]]y1+=[i[1]]plt.plot(x1,y1, 'o',color='b')## 画初始的点,把一个二维数组拆成一维def draw_center(cs):x1=[]y1=[]for i in cs:x1+=[i[0]]y1+=[i[1]]###print(x1)plt.plot(x1,y1, 'o',color='r')##plt.scatter(i[0],i[1],'o',color='r')## 画聚类中心## 聚类个数 kmeans中的kx=np.random.randint(0,100,(100,2))print("初始数据:")print(x)## 随机一个二维数组draw_initial_point(x)initial_centers = kmeans_plusplus_initializer(x, cluster_num).initialize()kmeans_instance = kmeans(x, initial_centers)kmeans_instance.process()clusters = kmeans_instance.get_clusters()cs = kmeans_instance.get_centers()## 详见:https://segmentfault.com/a/1190000039785725print("聚类中心:")print(cs)draw_center(cs)print("分类情况:")print(clusters)print("test:")##plt.plot(x1,y1, 'o',color='b')add_line_between_center_and_members(cs,clusters,x)plt.show()

上手用自定义距离聚类
#以下代码为:生成随机散点图from turtle import colorimport osimport numpy as npimport matplotlib.pyplot as pltfrom pyclustering.utils.metric import distance_metric, type_metricfrom pyclustering.cluster.kmeans import kmeans, kmeans_visualizerfrom pyclustering.cluster.center_initializer import kmeans_plusplus_initializerfrom pyclustering.cluster import cluster_visualizerfrom pyclustering.samples.definitions import FCPS_SAMPLESfrom pyclustering.utils import read_sample## 前面是安装的库inpath = "./save_bignum"datanames = os.listdir(inpath)slen=len(datanames)x=np.random.randint(0,1,(slen,2))mp=np.random.randint(0,1,(slen+1000,slen+1000))for i in range(0,slen):x[i,0]=i+1x[i,1]=1print(x)def my_manhattan(p1,p2):print(str(p1[0])+" "+str(p2[0]))if mp[p1[0]][p2[0]]:return mp[p1[0]][p2[0]]f1=open(inpath+'/'+str(p1[0]))f2=open(inpath+'/'+str(p2[0]))s1=int(f1.read())s2=int(f2.read())f1.close()f2.close()s=s1 ^ s2ans=0while(s):if(s&1):ans+=1s>>=1mp[p1[0]][p2[0]]=mp[p2[0]][p1[0]]=ansreturn ansmy_metric = distance_metric(type_metric.USER_DEFINED, func=my_manhattan)cluster_num=100initial_centers = kmeans_plusplus_initializer(x, cluster_num).initialize()kmeans_instance = kmeans(x, initial_centers,metric=my_metric)kmeans_instance.process()clusters = kmeans_instance.get_clusters()cs = kmeans_instance.get_centers()
Screen用法
创建
screen -S [Name] ##创造一个名字为Name的screenscreen -ls ##看查当前所有screen和编号

连接
screen -r [ID]ps:如果连不上,先screen -d[ID]再-r
screen -X -S [ID] quit参考文献

看雪ID:Nameless_a
https://bbs.pediy.com/user-home-943085.htm

# 往期推荐

球分享
球点赞
球在看

点击“阅读原文”,了解更多!
[广告]赞助链接:
关注数据与安全,洞悉企业级服务市场:https://www.ijiandao.com/
让资讯触达的更精准有趣:https://www.0xu.cn/
 关注KnowSafe微信公众号
关注KnowSafe微信公众号随时掌握互联网精彩
- Deepseek官网入口 Deepseek网页版登录地址
- 字节跳动静态资源公共库因黑产原因下线 此前部分资源已经中断数月
- 微信内测查删单向好友功能上热搜 网友:不用转账测试了
- 高通推出第一代骁龙6和第一代骁龙4移动平台,将旗舰特性下沉带给更多消费者
- 【程序员的趣味生活】软弱?硬气?你是哪种程序员
- GitHub上数量第2多的中国开发者,如何在收入上赶上同行?
- 魅族18系列:轻妙纯粹,天生好感
- 图解霍夫曼编码
- 破圈!不止于浏览器,WebAssembly 2020 大事记
- 当音乐博士开始写代码...
- 对话DigiCert Perry Chen:数字证书是互联网安全的根基
- 手机浏览器地址栏欺骗漏洞曝光,无法有效查看SSL证书是导火线!
赞助链接




