算力增强很容易,内存提升却愈来愈难

【CSDN 编者按】内存的性能指标主要有“带宽”和“加载时间”,当内存性能与 CPU 性能不匹配时,就产生了内存墙,本文以杰克·唐加拉在图灵奖主题演讲为引子,对如何打破“内存墙”做了一些思考,希望未来软硬件能够协同设计,从而解决内存墙的问题。
原文链接:https://www.nextplatform.com/2022/12/13/compute-is-easy-memory-is-harder-and-harder/
在一个时钟周期内,如果无法以足够快的速度获取数据,从而使用计算引擎以某种方式处理它,那么包含在矢量或矩阵单元中的浮点运算又有什么用呢?答案显然是没啥用。
几十年来,人们一直在讨论计算和内存带宽之间的不平衡,而且每年高性能计算行业都不得不接受单位浮点运算所对应的内存带宽越来越低的现实,因为增加内存带宽在某种程度上非常困难,而且最终成本也非常高昂。
而在我们考量这个问题的同时,增加内存容量也变得越来越困难,因为内存扩容也面临着摩尔定律的压力,这让厂商越来越难以制造出密度更高、速度更快的内存,因此内存的价格不降反升。换言之,几十年前梦想的那种大容量存储机器并没有出现。
杰克·唐加拉( Jack Dongarra) 在图灵奖主题演讲中,敏锐地提到了这一点。他是 Oak Ridge National Laboratory 计算机科学与数学部杰出研究人员,兼田纳西大学电气工程与计算机科学系特聘教授,被 The Next Platform 读者所熟知。唐加拉在图灵奖主题演讲中讲述了他如何出人意料地进入了超级计算机行业,并成为衡量这些超级计算机系统性能的专家——主要是因为他是团队的一员,随着超级计算机架构每十年左右发生变化,该团队不断改进数学库。如果还没有看过这篇主题演讲,建议你看一看(https://www.youtube.com/watch?v=cSO0Tc2w5Dg)。这段历史令人着迷,它预测了随着架构的不断发展,我们将如何继续发展软件。
当观看唐加拉的主题演讲时,脑海中浮现的是当今处理器中相对于内存带宽的大量超额配置,让人产生共鸣,同一周,英特尔宣布了即将推出的“Sapphire Rapids”至强 SP 服务器 CPU 的一些基准测试结果,显示了 HBM2e 堆叠内存的优势,其内存带宽大约是现代服务器 CPU 中使用的普通 DDR5 内存条的 4 倍。(Sapphire Rapids 提供 64 GB HBM2e 内存选项,可以与 DDR5 内存一起使用,或选择 HBM2e。)HBM2e 高带宽内存的优势表明,故障率和带宽的关系有多大,如下图:
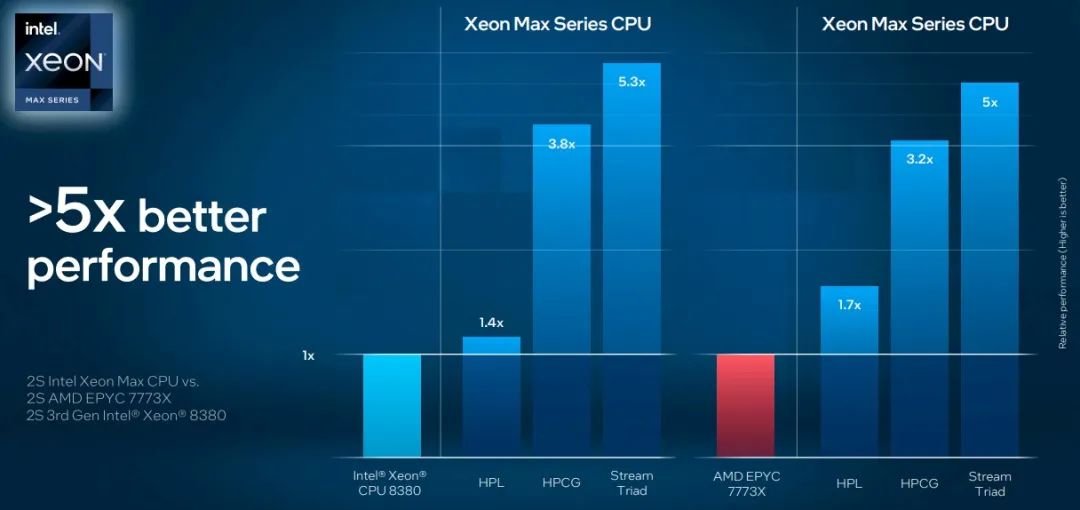
如您所见,向 Sapphire Rapids CPU 添加 HBM2e 内存并不会对杰克·唐加拉钟爱的高性能 Linpack (HPL) 矩阵数学基准测试产生太大影响,这是因为 HPL不受内存限制。但是高性能共轭梯度(HPCG:High Performance Conjugate Gradients)和 Stream Triad 基准测试,受内存影响非常大,确实可以通过转向 HBM2e 实现性能提升(我们假设测试的机器有一对 top bin,60 核 Sapphire Rapids 芯片)。在正常情况下,HPCG 测试可能是最准确的测试,反映了一些非常困难的 HPC 应用程序的真实编写方式(而且是出于需要,而不是选择),考虑到全球最快超级计算机的各时段平均算力利用率也就 1% 到 5% 之间,那么将 3.8 倍的性能提升扩展到数千个节点,确实会带来非常大的改进。(这一点还有待观察,HPCG 是将(或不会)显示它的测试。
那么,flops 和内存带宽之间到底有多大差距?杰克·唐加拉展示了随着超级计算的每一次架构革命的到来,情况变得越来越糟糕:

下面是唐加拉展示的图表的放大图:

“当我们在今天的机器上查看性能时,会发现数据移动才是制约速度的瓶颈,”Dongarra 解释道。“我们研究浮点执行率除以数据移动率,研究不同的处理器。在过去,处理器基本上每一次数据移动都匹配一flops——这就是它们的平衡方式。大家可能还依稀记得原先的 Cray-1s,可以同时进行两个浮点运算和三个数据移动。但随着时间的推移,处理器改变了平衡。
在接下来的二十年里,这种失衡又扩大了一个量级。也就是说,现在每次数据移动执行十次浮点运算。而最近,我们甚至发现每次数据移动开始对应上百次、甚至 200 次浮点运算。也就是说,浮点数和数据移动之间存在巨大的失衡。所以我们拥有强大的算力——为算力提供了过多的资源——但在系统中没有非常有效地移动数据机制,也就是说这些算力根本用不起来。”
从图表中可以看出,随着超算系统架构的升级,失衡状况也变得越来越严重。我们认为,转向 HBM2e 甚至 HBM3 或 HBM4 和 HBM5 内存只是一个开始。CXL 内存也能部分解决这个问题。由于 CXL 内存的速度比闪存快,所以我们喜欢将其作为系统架构师的工具。但是系统中只有这么多的 PCI-Express 通道可以在节点内部进行 CXL 内存容量和内存带宽扩展。尽管共享内存很有趣,而且对于 HPC 模拟和建模以及 AI 训练工作负载可能非常有用——同样,因为它的性能比闪存更高——但这并不意味着这一切都能负担得起。
我们还不清楚 Sapphire Rapids 上的 HBM2e 内存选项的成本是多少。如果它将内存受限的应用程序性能提高了 4 到 5 倍,但 CPU 的成本却增加了 3 倍,那么这并不是真正意义上的功率性能提升,而这正是架构选择的关键所在。
新一代至强 SP 上的 HBM2e 内存选项是朝着正确方向迈出的一大步。但如果想让算力和内存恢复平衡,可能在 L1、L2 和 L3 缓存中拥有更多的 SRAM 比添加内核更重要。
获得图灵奖,唐加拉有机会对这个行业进行一番说教,他很感激有这样一个机会。下面详细引用他的原话,希望大家认真倾听。
“我一再强调机器的失衡,”唐加拉说。“时至今日,我们基于 AMD 或英特尔的现成商用处理器、加速器、现成的互连线来建造机器,并没有根据将要用于驱动它们的应用程序的具体情况来设计硬件。所以也许我们应该退后一步,仔细看看架构应该如何与应用程序交互,与软件协同设计,但现实是今天很少有与硬件协同设计的情况。可以从这些数字中看出,协同设计的情况很少。也许一个好的——更好的——指标,正在日本产生,在日本,架构师与硬件人员有更密切的互动,从而一起设计出具有更好平衡的机器。因此,如果要着眼于前瞻性研究项目,接下来是时候把注意力转回架构上来了,并让架构更好地反映在应用程序中。总之,我们应当在硬件、应用程序和软件之间取得更好的平衡——真正参与协同设计。我当初上大学的时候,学校正在开发将机器组装在一起的架构。伊利诺伊州就是一个很好的例子——斯坦福大学、麻省理工学院、CMU。其他地方成立了硬件项目,正在研究架构。今天,我们看不到这种情况。也许我们应该考虑把一些研究资金——也许是能源部的资金——投入到这项工作的机制中。”
我们完全同意硬件-软件协同设计,认为架构应该反映运行它们的软件。坦率地说,如果一台 exascale 机器的成本为 5 亿美元,但只能使用 5% flop 来做实际工作,那么考虑性价比的话,这就好比花 100 亿美元购买一台以 100% 利用率运行的 100PB 浮点运算机器。按照唐加拉建议的方式去做,未来所有超级计算机将更加独特,虽然通用性降低,设计成本也更高,但其每瓦性能、单位算力成本、单位内存带宽性能和单位内存带宽成本都将远远优于现有超算在 HPCG 等测试中的表现。我们必须让这些 HPC 和 AI 架构重新步入正轨。
受到唐加拉和他同行的启发,未来的研究人员需要解决这个内存带宽问题,而不是将其掩盖,放任不管。或者,用一个很好的隐喻形象来说更好——不要像暴徒袭击那样把它卷在地毯里,然后把它放进林肯车的后备箱,扔到草地上。事实上,100 倍或 200 倍的差距是一种经济犯罪的表现。

☞华为天才少年稚晖君被曝离职;苹果 A16“挤牙膏”原因曝光;Ruby 3.2.0 发布|极客头条 ☞Google 拉起「红色警戒线」,应对 ChatGPT 的巨大威胁! ☞年薪达 35 万元,杭州成为薪酬最高的城市,北上、重庆通勤时间最久,揭晓 2022 年最具潜力的软件名城!
[广告]赞助链接:
关注数据与安全,洞悉企业级服务市场:https://www.ijiandao.com/
让资讯触达的更精准有趣:https://www.0xu.cn/
 关注KnowSafe微信公众号
关注KnowSafe微信公众号随时掌握互联网精彩
- 鸿蒙版微信1.0.7.39正式版发布:支持收藏内容转发、长按翻译
- Debian上PostgreSQL如何进行数据恢复
- Ngrok 内网穿透工具
- 较为前沿的9个API安全工具
- 大疆无人机被检测出16个安全漏洞
- 优酷“首月1元”会员引争议:取消续费却被扣24元;马斯克欲在推特建立支付系统,并包含加密货币功能;Deno 1.3发布|极客头条
- 印度外交部泄露其海外居民的护照详细信息
- 详解 SSL(三):SSL 证书该如何选择?
- 历史上的今天:Apple II 问世;微软收购 GECAD;发明“软件工程”一词的科技先驱出生
- 全球37%智能手机可遭窃听,联发科芯片爆安全漏洞
- Windows 的开发好痛苦
- GitHub 宣布拆“墙”,恢复伊朗开发者使用权!




